The big question
How did life originate? It’s a question with far-reaching implications, and its investigation can provide insight into many other questions. Is life unique to Earth, rare, or even commonplace in our solar system, galaxy or observable universe? Are we native to Earth, or did life originate someplace else and somehow make the journey here, perhaps via a meteorite (Fig. 1)? By formulating and testing hypotheses about the rise of living cells from inanimate chemical systems, we can expect to propose satisfying answers to these questions that relate to our place in the universe. Furthermore, we stand to gain significant insight into health and medicine by reconstructing life’s origins.
As the saying goes, you never really understand how something works until you can take it apart and put it together again, and when it comes to life, whilst (molecular) biologists are good at characterising its organisation and complexity, we are yet to understand how these qualities can spontaneously arise from simpler building blocks. What follows is a description of some problems with studying the origins of life, and what directions modern research has taken in response to these.

Life and prebiotic chemistry
To formulate a systematic approach to studying the origins of life, it would first be nice to settle on a definition of what life is. Such a definition would also be enormously helpful in our search for extra-terrestrial life, which is expanding rapidly with equipment such as the James Webb Space Telescope - the largest telescope in space - which started delivering images, including previously undetected exoplanets potentially ripe for life, less than six months ago. The difficulty here, though, is that life on Earth is so complex and diverse that a definition, from which to approach the origins question, is tricky.
One helpful qualifier is to state that usually when we discuss life and its origins, we mean ‘life-as-we-know-it’. Life-as-we-know-it has an incredible number of dazzling forms and functions, but all are underpinned by the same core biochemistry. Thus, unravelling the mystery of life’s origins is best approached in terms of understanding its chemistry. Prebiotic chemistry is the discipline that seeks to evaluate which building blocks of biological relevance pre-existed enzymes and biosynthesis and the ways in which they may have interacted to ultimately form living systems.
Life revolves around the central dogma
Biochemistry has several important functions, with perhaps the most prominent themes among these being of replication, homeostasis, information and adaptation. For life, these themes are inseparable. Life is a ‘thing’ (i.e. information), that seeks to continue its existence. To do so, it needs to maintain an ideal set of conditions for its persistence and replication - homeostasis. To this end, it has developed an array of sophisticated chemical strategies to take in energy from the surrounding environment - whether it be heat, light, or chemical fuel - and use it to control its immediate, cellular environment. The development and maintenance of these chemical techniques has come about from an amazing ability to adapt, based on the storage, replication and decoding of information, which at every generation is iteratively varied and optimised by the processes of variation and selection.
Remarkably, biology deals with information at a chemical level in much the same way we do in a didactic sense. Biology writes information, using an alphabet of DNA molecules (A, T G and C), in much the same way we would write an instruction manual for furniture assembly, or a recipe. Biological instruction manuals – genes - are translated by the ribosome into functional proteins that protect and replicate genomes and allow the organism carrying them to thrive. Nucleic acids are the only means by which we have seen this biological information cycle occur. Thus, all extant biochemistry is related because it is all geared towards the same goal of perpetuating and decoding information stored in the same molecules: nucleic acids. This is why you and I have the same genetic code, and indeed many very similar proteins, as bacteria and plants. Francis Crick’s central dogma of biology depicts the flow of information into function in biology (Fig. 2).
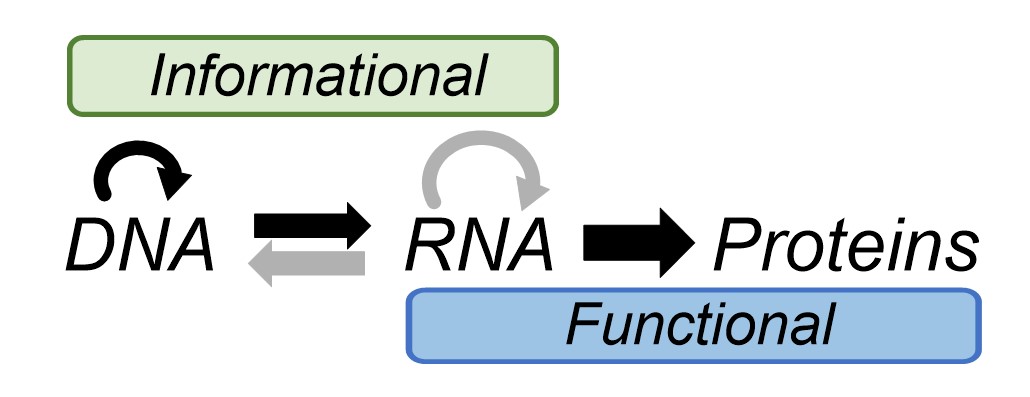
Generally speaking, the division of labour in the cell among the three biopolymers is that DNA stores information, proteins carry out the functional tasks relating to homeostasis and replication and RNA does a bit of both. Getting back to a definition of life, and therefore figuring out how it may have started, whilst nucleic acids are essential for information storage in biology as we know it, some suggest that information could be stored, translated into function and perpetuated in other ways. For example, the microscopic shape of the surface of a mineral could influence the catalysis of self-sustaining chemical reactions (autocatalysis) on it. Would this constitute life? Alternatively, other simpler molecules might store information in a similar way to nucleic acids.
If other ways of storing and perpetuating biological information exist, then they could have preceded the nucleic acid-based life we know, and may still exist elsewhere in the universe. This idea is attractive to some because they argue that nucleic acids are so complex (see below) that they must be the biosynthetic progeny of some ancestor of modern biochemistry that subsequently disappeared, driven to extinction by competition for resources, in much the same way birds usurped the dinosaurs, or modern humans replaced their less adapted ancestors (Fig. 3).
Others maintain that there can be no replicable and decodable biological information without nucleic acids, and thus, evolution could have only begun with them. So, to summarise, biochemistry gives us a well-defined idea of what life is for all the (related, nucleic acid-based)organisms on Earth, but a more abstract definition for life, which would help us in our investigation of its potential beginnings here, and our search for it outside Earth, is harder to agree upon. Hopefully, when it comes to the extra-terrestrial world, we’ll know life when we see it.

Too complex?
So, now that we’ve briefly considered the definition of life, we can broaden and reformulate our initial question. Firstly, is life possible, and does it or has it existed, with a biochemistry and set of molecules different to the ones we know? Now we can start to see how this leads into open-ended chemical research. Could we recapitulate some of the cycles of life with wholly different molecules? Wholly different types of chemical interactions? And secondly, more to the initial question, what processes and conditions led to the rise of extant biochemistry, i.e. the central dogma, on Earth?
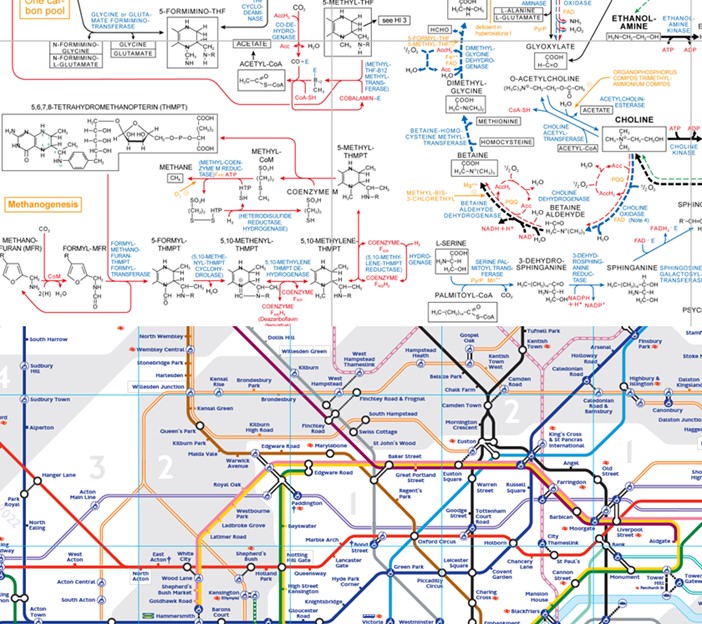
Those first questions I have posed are very interesting and open-ended. But the last one is probably more pressing, because it relates directly to our own origins. At the outset, it seems a dauntingly difficult question, because one of life’s hallmarks is complexity. Anyone who has studied biochemistry knows that even simplified biochemical charts are far more complex than a map of the London tube network (Fig. 4). This certainly makes the attempt to understand the origins of this system seem difficult.
We can reduce the problem as much as possible, by considering the simplest known free-living organism, or the one with the genome encoding the least information: Mycoplasma genitalium.1 This bacterium has the smallest genome known, composed of just over 500 information-storing genes, in a polymer of about 600,000 monomeric DNA units. Could the information stored in this genome have occurred in an entirely random process, akin to monkeys on typewriters writing Shakespeare?
Let us assume that the monomers comprising the genetic alphabet were abundant and accessible on the early Earth. Given a pristine pool containing the four monomers of DNA (A, T, G and C) the likelihood of this genome emerging at random, is vanishingly, vanishingly, small. For some context, if you converted the entire mass of the earth into DNA, you could only make one copy of every different DNA polymer up to eighty bases long. Taking the mass of the universe would only get you as far with polymers up to 125 bases long! That’s a far cry from hundreds of thousands, and when you consider that this fully functioning organism needs more than just DNA but a cell membrane, a variety of amino acids and other metabolites, an entirely random origin of even the simplest organism known would be an unbelievably rare event, even assuming complex molecules like RNA and DNA polymers formed on Earth. Thus, it would be helpful to refine our approach.
A minimal requirement for life?
Firstly, we need to discover just how minimal a system constituting life can be. It’s reasonable to assume we can go simpler than Mycoplasmagenitalium,2 because even today’s simplest organism has a family tree stretching back about 4 billion years to life’s origins and has benefitted enormously from the continual trial and error cycle of variation and selection that underpins Darwinian evolution.
Improvements on this front are hard-won, though. Since the rise of whole-genome sequencing in the 1990s, synthetic biologists have been working towards creating the prototypical ‘minimalist organism’, i.e. one with the smallest genome possible. So far, the best efforts have yielded a bacterium with about 50,000 fewer base pairs than Mycoplasma genitalium. It’s an impressive achievement, but in the context of the origin of life, scientists are still hotly debating the origin of just single RNA or DNA monomers, let alone polymers of half a million bases. In other words, there is still an enormous gap in understanding how the first, primitive organisms could have arisen from the primordial soup.
The RNA world
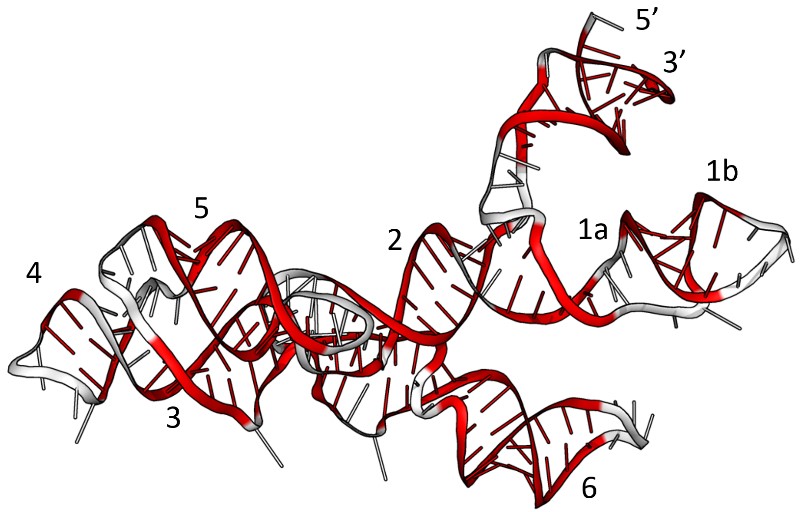
A simpler alternative is to aim for a prototypical ‘organism’ that doesn’t bother with the whole business of having a cell and proteins, or even DNA: a stripped down, self-replicating RNA, or a community thereof. Since RNA and DNA are both capable of storing information, we could conceivably leave DNA out of the central dogma and maintain some of its function. Going a step further, since RNA molecules can also be capable catalysts themselves, if generally less efficient than proteins, we could even remove proteins from the central dogma too, leaving us only with RNA. In fact, RNA polymers, named ribozymes (Fig. 5) because they can have similar functions to enzymes, yet are made only from ribonucleic acids (RNA) for example, a heterodimeric pair each consisting of about 150 bases, have been shown to copy themselves under certain laboratory conditions.3 In principle, this reduces the complexity of the origin of life problem (which for life as we know it includes the origin of DNA, RNA, proteins and cells), into the origin of RNA.
RNA biology, operating under natural selection, could then give rise to the ribosome, and hence proteins, and DNA, which established the central dogma. This idea, termed the ‘RNA World’, is consistent with several tantalising pieces of evidence. However, whether ribozymes could form, continuously replicate and evolve, outside of carefully controlled lab conditions, is still very much an open question, leading others to still favour the ‘wholistic’ nucleic acids/proteins origins scenario. Although this scenario seems more complex, they argue that the intrinsic chemical properties of biomolecules lend themselves towards cooperativity and ever-increasing levels of organisation and complexity.
Apparent complexity
Whilst for this case study in chance we have discussed the formation of functional polymers from monomers, similar arguments apply to the formation of monomers themselves. For example, the molecule adenosine 5’-phosphate, ‘A’ in the genetic alphabet, is composed of 37 atoms and 31 bonds. There are 16 stereoisomers of adenosine and millions of ways of arranging the atoms into different constitutional isomers. Thus, for molecules like nucleotides to arise on Earth seems similarly unlikely as their polymerisation into functional genomes. The spontaneous emergence by random processes of a simple organism therefore seems an impossibly unlikely event. Although improbable events do occur, it would help if there were something special about Earth’s early chemistry, and the chemistry of biomolecules - some aspect of their predisposed reactivity - that makes the synthesis and coalescence of individual and disparate molecules like nucleotides, amino acids and fatty acids (the constituents of cell membranes) more likely than just a random process. This reduces complexity to apparent complexity, a term used by Albert Eschenmoser in the context of origins of life chemistry,4 and would mean that the processes leading to the origin of life have a chance to occur in multiple times and locations, including our laboratories.
Predisposed reactivity
A classic synthesis, oft mentioned in organic chemistry classes, is Robert Robinson’s of tropinone in 1917.5 It is remarkable because, by looking at the structure of tropinone, it seems too complex to assemble in just two operations, and its structure does not map all that well onto that of the starting materials. But Robinson showed that the complexity of tropinone is only apparent because if you take the simple starting materials and conditions he chose, Nature’s rules dictating their predisposed reactivity leads these materials to reliably combine to form tropinone in good yield.
In prebiotic chemistry, Oró’s subsequent 1960 discovery,6 further elaborated by Wakamatsu et. al,7 that heating a mixture of two simple molecules, ammonia and hydrogen cyanide, could lead in good yield to a heterocycle as complex as adenine, was equally stunning (Fig. 6). When looking at the products of these reactions, it is difficult to come up with the starting materials because of their structural dissimilarity to the products. Critically, despite the seemingly massive increases in complexity in the transformations, they are entirely reproducible, giving the same result each time they are repeated. The complexity produced is not a random accident. Furthermore, as knowledge of structure and mechanism grew, the reactions became rationalisable and even predictable on related systems. By understanding the principles at work, what initially seems like an intractable puzzle can be tamed.
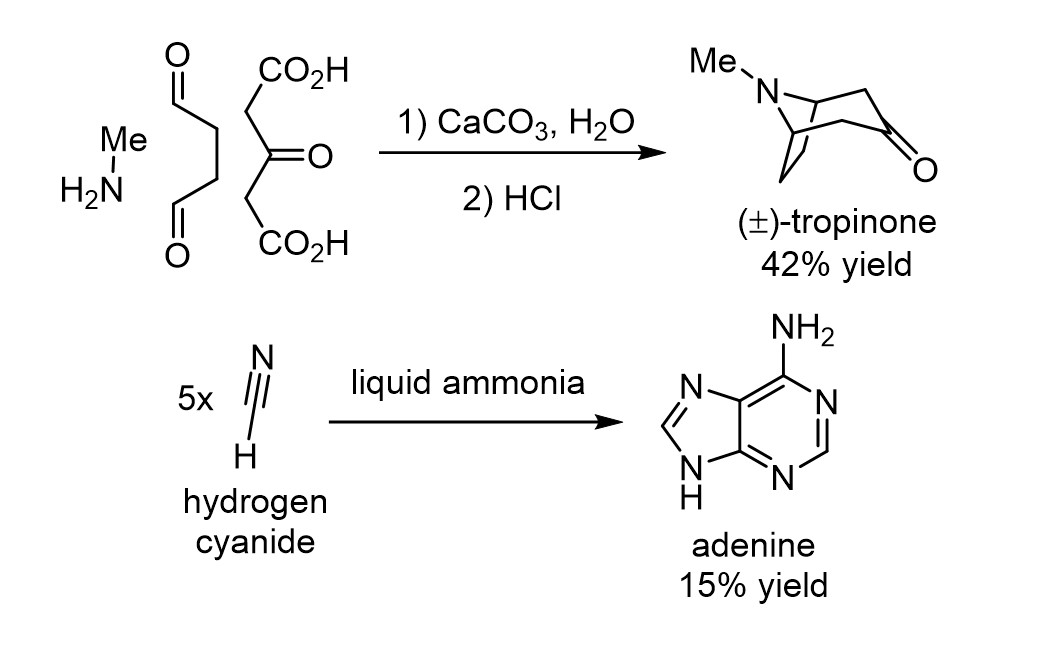
Predisposed or random accident?
If predisposed reactivity of chemical building blocks, leading to the type of apparent complexity that adenine exhibits, was realised at multiple stages in the transition of simple matter into a living system, then much of the complexity of biology may be apparent. As a consequence, studying the chemical behaviour of these building blocks, which might be consistent in a variety of conditions, rather than unique for every set of variables, should yield rationalisable, predictable and reproducible increases in complexity on a trajectory towards that of biology.
So just how much of life’s early journey may have been predisposed? Since Oró’s seminal work, intensive studies in prebiotic chemistry have yielded many exciting discoveries in chemistry about properties of biomolecules hinting that the structures of much of life’s complex inventory, and the way it interacts with itself, may be predisposed. Experiments like Stanley Miller’s show that many conditions favour the production of some biomolecules, such as amino acids, because of predisposed reactivity.8
Albert Eschenmoser showed that chemical relatives of modern biomolecules can have similar properties, widening the array of possible molecules that might have been sufficient to kickstart biological information cycles.9 The likes of Oro and Orgel showed that the chemistry of certain hypothetical local geochemical environments, recreated in a laboratory, and not subject to the same ‘averaged out’ constraints as oceans and atmospheres, can produce biomolecules and their precursors and relatives with surprising selectivity.10 This has culminated in the last 15 years with various demonstrations that even the seemingly complex monomers of life’s central molecules, nucleic acids, can form in surprisingly few steps and with surprisingly high selectivity, if the conditions are right, and vary at the right times.11 Because of such work, the question of chance now moves away from, “What are the chances of a unique molecule like this forming in a soup of random interactions?” to “What are the chances of certain conditions prevailing at certain times, and therefore leading to molecules with these properties?”
Finding the path
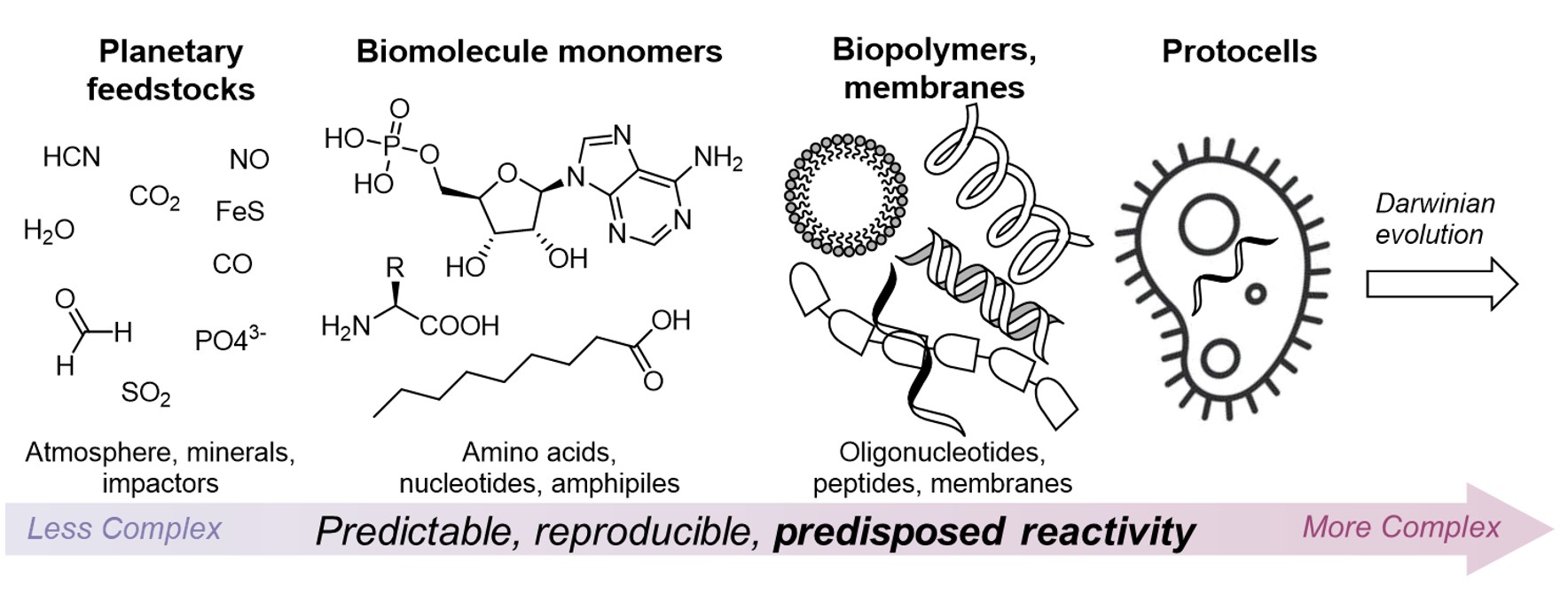
Is life a random accident? Or, given a certain type of planet and conditions, is it ultimately a likely expression of planetary chemical processes, or even inevitable? Whilst chance, or stochastic events, certainly have a role to play, for example in the timing and location of events that influence local geochemistry, such as meteorite impacts and volcanic eruptions, a tenet of much origins of life research is that the chemical processes leading to the transition in complexity of the earth’s chemical inventory, from simple planetary feedstock minerals and gases, to the complex networks of organic metabolites exchanged across the global ecosystem, is rationalisable and, to a large extent, predictable and reproducible.
This means that, rather than a simple organism or ecosystem arising randomly as one of countless possible arrangements of atoms available, the processes that led to the rise of life may have only flowed through certain pathways allowed by virtue of the reactivity of the building blocks in question and the conditions that prevailed and thus are, to some degree, deterministic (Fig. 7). Traversing these pathways, in prebiotic chemistry, and seeing where they lead, is an exciting and thriving area of research.
References
- Glass, J. I.; Assad-Garcia, N.; Alperovich, N.; Yooseph, S.; Lewis, M. R.; et al. Proc. Natl. Acad. Sci. U.S.A.2006, 103 (2), 425–430.
- Hutchison, C. A.; Chuang, R.-Y.; Noskov, V. N.; Assad-Garcia, N.; Deerinck, T. J.; et al. Science 2016, 351 (6280).
- Wachowius, F.; Holliger, P. RNA Replication and the RNA Polymerase Ribozyme. In Ribozymes; Wiley, 2021; pp 359–386.
- Eschenmoser, A. Angew. Chemie Int. Ed. English 1988, 27 (1), 5–39.
- Robinson, R. J. Chem. Soc. Trans. 1917, 111 (0), 762–768.
- Oró, J. Biochem. Biophys. Res. Commun. 1960, 2 (6), 407–412.
- Wakamatsu, H.; Yamada, Y.; Saito, T.; Kumashiro, I.; Takenishi, T. J. Org. Chem. 1966, 31 (6), 2035–2036.
- Bada, J. L. Chem. Soc. Rev. 2013, 42 (5), 2186.
- Schenmoser, A. Science 1999, 284 (5423), 2118.
- Joyce, G. F. Nature 2007, 450 (7170), 627–627.
- Xu, J.; Chmela, V.; Green, N. J.; Russell, D. A.; Janicki, M. J.; et al. Nature 2020, 582 (7810), 60–66.